
Mathworks firması tarafından hazırlanan ve 4 bölümden oluşan Makine Öğrenmesi e-kitaplarını/sunularını okurken bazı yerleri not etmek istedim. Benim notlarıma bakmadan kendiniz okumak isterseniz aşağıdaki bağlantılardan erişebilirsiniz.
1. 1-Introducing_Machine_Learning
2. 2-Getting_Started _with_Machine_Learning
3. 3-Applying_Unsupervised_Learning
4. 4-Applying_Supervised_Learning
1-Makine Öğrenmesine Giriş (Introducing Machine Learning)
Bilgisayarların insanlar ve hayvanlar gibi deneyimlere dayalı bir şekilde öğrenme yapmasına makine öğrenmesi denir.
Makine öğrenmesi veri setleri içerisindeki örüntüleri ortaya çıkarmaya çalışmaktadır. Verinin büyümesiyle makine öğrenmesinin önemi daha da artmıştır. Bir çok gerçek dünya problemine makine öğrenmesi teknikleriyle çözüm aranmaktadır. Örneğin;
Hesaplamalı finans (Computational finance):
Kredi skorlaması (credit scoring)
Algoritmik ticaret (algorithmic trading)
Görüntü işleme ve bilgisayarla görme (Image processing and computer vision)
Yüz tanıma (face recognition)
Hareket algılama (motion detection)
Nesne algılama (object detection)
Hesaplamalı biyoloji (Computational biology)
Tümör bulma (tumor detection)
İlaç keşfi (drug discovery)
DNA dizilimi (DNA sequencing)
Enerji üretimi(Energy production)
Fiyat ve yük tahmini (price and load forecasting)
Otomotiv, havacılık ve üretim (Automotive, aerospace, and manufacturing):
öngörücü bakım (predictive maintenance)
Doğal dil işleme (Natural language processing)
Makine Öğrenmesi Teknikleri, supervised(denetimli,gözetimli,eğiticili) ve unsupervised(denetimsiz,gözetimsiz,eğiticisiz) şeklinde ikiye ayrılmaktadır. Gözetimli öğrenme Sınıflandırma ve Regresyon alt alanlarına, gözetimsiz öğrenme ise Kümeleme alt alanına ayrılmaktadır.

Gözetimli öğrenmede girdi ve çıktı verileri kullanılarak sistem öğrenmeye çalışır. Gözetimsiz öğrenmede ise sadece girdi verilerinden bir sonuç üretilmeye çalışılır.
Makine Öğrenmesi Algoritmaları
Çok sayıda vardır ve her geçen günde sayıları artmaktadır. Probleminize göre en uygun algoritmayı bulmak deneme yanılma metoduyla biraz zaman alabilir. Geçmiş çalışmalardan veri setinize en uygun çözümleri kimlerin ürettiğini inceleyerek bir çıkarım yapabilirsiniz.

Makine Öğrenmesi ne zaman kullanılır?
Elimizde çok büyük veri ve çok sayıda özellik var bunları yorumlayacak denklem veya fonksiyonlarımız yok ise bir anlam çıkarmak için makine öğrenmesi kullanılabilir. El yazısı tanıma, dolandırıcılık algılama, sürekli artan veriye sahip alışveriş trendleri gibi problemlerin çözümünde kullanılabilir.
İlginç Gerçek Dünya Problemleri
66 ressamın 550 yıla dağılmış 1700 farklı tablosu ile hazırlanmış bir makine öğrenmesi Diego Velazquez’in Papa Masum X’in portresi çalışmasıyla Francis Bacon’un Velazquez’in Papa Masum X’ten Sonra Çalışması tablolarının ilişkili olduğunu bulmuştur.

Isıtma, havalandırma ve klima (heating, ventilation, and air-conditioning (HVAC)) sistemlerinin optimizasyonu ile %10-%25 arası bir tasarruf sağlanmıştır.
Düşük Hızlı Araba Çarpmalarını Tespit Etme uygulaması %92 doğrulukla geliştirilmiştir.
2-Makine Öğrenmeye Başlarken (Getting Started with Machine Learning)
Makine Öğrenmesi sürecinde iyi bir sonuç elde etmek için bir çok yöntem ve yaklaşımla karşılaşılacaktır. Şu ana kadar edinilen tecrübeler ışığında bazı ana yorumlar yapılabilir.
-Veri setleri farklı şekillerde ve büyüklüklerde olabilir.
-Farklı veri tipleri farklı veri ön işleme aşamaları gerektirebilir.
-Doğru modeli seçmek en önemli aşamadır. Probleminize göre model hızı, doğruluğu ve karmaşıklığı parametrelerinden hangisine daha çok önem vereceğiniz ve hangisine daha çok ödün verebileceğiniz size kalmış durumdadır.
DENEME YANILMA MAKİNE ÖĞRENMESİNİN TEMELİDİR. Önemli olan yılmadan, başka yöntemleri de deneyerek başarılı bir sonuç elde etmeye çalışmaktadır.
Bir makine öğrenmesi süreci şu 3 soruyla başlar:
1-Hangi tür veriyle çalışıyorsunuz?
2-Ne elde etmeyi umut ediyorsunuz?
3-Elde ettiklerinizi nerede ve nasıl kullanacaksınız?
Tahmin ve sınıflama için gözetimli öğrenme, kümeleme için gözetimsiz öğrenme metodlarını kullanmalısınız.
Bir Bakışta İş Akışı:
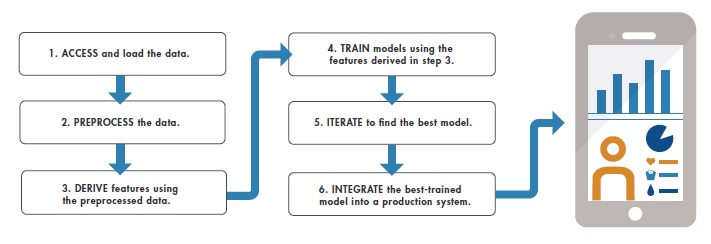
Örnek: Mobil Cihazlar üzerinde çalışan Sağlık Durumu İzleme Uygulaması
Girdi: Telefonun ivmeölçerinden ve jiroskopundan gelen üç eksenli sensör verilerinden oluşur.
Çıktı: Yürümek, ayakta durmak, koşmak, merdiven tırmanmak veya yatmak
Amaç: Girdileri kullanarak bir sınıflandırma modelini eğitip aktiviteleri tahmin etmek
Sonuç:Kullanıcılara yaptıkları aktiviteleri sonuç olarak göstermek

1.Adım: Verinin Yüklenmesi
İvmeölçerden(accelerometer) ve jiroskopdan(gyroscope) gelen verilerle:
-Telefonu oturarak tutuyorsa: ‘Sitting’
-Telefonu ayakta tutuyorsa: ‘Standing’
-Sınıflandırma işlemi bitene kadar yukarıdaki durumlar tekrar edilir.
durumları bir text veya CSV dosyasına kaydedilir.
Makine öğrenmesi henüz gürültülü verilerle mücadele konusunda çok başarılı olmadığından veri setinin temiz ve tam olması gerekmektedir.
2.Adım: Veri Ön İşleme
1-Gürültülü verilerin tespit edilmesi ve ayıklanması
2-Eksik verilerin tespit edilmesi ve enterpole veya başka yöntemlerle tanımlanması
3-İvmeölçerden gelen yerçekimi ile ilgili verilerin ayıklanması (Bunun için biquad filtresi gibi basit bir yüksek geçiren filtre yaygın olarak kullanılır.)
4-Veri setini eğitim ve test olarak bölün. ()
Aktivite izleme veri setindeki aykırı (outlier) veriler aşağıdaki şekilde görülmektedir.

3.Adım: Özellik Çıkarımı
Ham datanın makine öğrenmesi algoritmalarının kullanacağı şekilde bir bilgiye dönüştürme sürecidir.
İvmeölçerden alınan veriler düşük frekansta ise yürüyor, yüksek frekansta ise koşuyor şeklinde bir özellik çıkarımı yapılmıştır.
Özellik çıkarımı:
• Bir makine öğrenme algoritmasının doğruluğunu geliştirir
• Yüksek boyutlu veri setleri için model performansını artırır
• Modelin yorumlanabilirliğini geliştirir
• Aşırı uyumu önler
Özellik çıkarımı işlemi sizin hayalgücünüze bağlı olsada bazı kabul edilmiş yöntemler aşağıdadır.

4.Adım: Modeli Kurmak ve Eğitmek
En hızlı ve kolay anlaşılır olan ile model kurmaya başlamalıyız. Örneğin Karar Ağaçları:
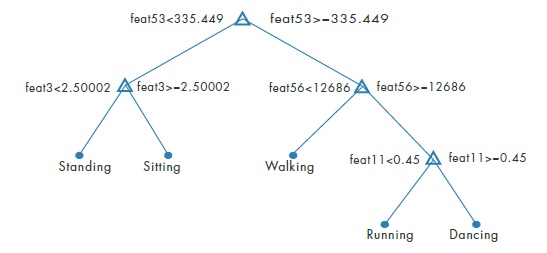
Modelin doğruluğunu kontrol etmek için karışıklık matrisi(confusion matrix) oluşturulur.

Görüleceği üzere dancing ve running durumlarında doğru kararlar verilememiştir. Bu yüzden başka modeller denemek gereklidir.
K-nearest neighbors (KNN) ile yapılan modellemenin sonuçları:

KNN iyi sonuçlar üretsede kullandığı bellek nedeniyle daha az bellek kullanan model arayışımız devam ediyor ve Destek Vektör Makineleri(support vector machine) ile yapılan çözüm:

5.Adım: Modeli Geliştirmek
Model basitleştirilerek veya karmaşıklaştırılarak geliştirilebilir.
Başarılı bir çözüme ulaştıktan sonra modeli basit hale getirmek hem anlaşılmasını kolaylaştırır, hem sağlamlığını artırır hem de karmaşıklığını azaltır.
Özellik indirgeme işlemi yapılabilir.
-Korelasyon Matrisi(Correlation matrix) oluşturulur, sonuca etkisi az olan özellikler çıkarılır.
-Temel Bileşen Analizi(Principal component analysis (PCA)): Temel bileşen analizi (PCA) – özgün özellikler arasındaki temel ayrımları yakalar ve veri kümesinde güçlü kalıplar ortaya çıkaran özelliklerin birleşimini bularak artıklığı ortadan kaldırır.
-Sıralı özellik azaltma – performans üzerinde herhangi bir iyileşme olmadıkça özellikleri modelden çıkartır.
Model kendi kendisine de özellik indirgeme yapabilir.
-Karar ağacından dalları budama
-Öğrenenleri topluluktan çıkarma
Karmaşıklık Ekleme
Hala istenen çözüm elde edilemiyorsa;
-Modeller birleştirilebilir.
-Yeni veri kaynakları eklenebilir.
Model istenen kalitede çözüm ürettiği zaman onu çalışacağı ortama aktarabiliriz.
3-Gözetimsiz Öğrenmeyi Uygulama(Applying Unsupervised Learning)
Veri içerisinde keşif yapma, verinin içinde ne tür bilgiler bulunduğunu bilmeme ve veri boyutunun azaltılması sürecinde gözetimsiz öğrenme kullanılabilir.
Kümeleme analizinde veriler benzerliklerine veya ortak özelliklerine göre kümelenir. Beklenen durum küme elemanları birbirleriyle oldukça benzer ve diğer küme elemanlarıyla oldukça farklı olmalıdır.
Temel olarak ikiye ayrılır:
-Hard Clustering: Veri tek kümede yer alır
-Soft Clustering: Veri birden fazla kümede yer alabilir.
Verinin nasıl kümeleneceğini bilmiyorsak:
-self-organizing feature maps
-hierarchical clustering
-cluster evaluation
kullanılabilir.
Yaygın Bilinen Kesin Kümeleme Algoritmaları
k-Means
-Veriyi k kümeye böler.
-Verileri küme merkezlerine uzaklıklarına göre gruplar.
-Küme merkezi kümedeki bir eleman değildir.
Artıları:
Küme sayısı bilindiği zaman iyi çalışır.
Büyük veri setlerini hızlı kümeler
k-Medoids
k-Means ile aynıdır sadece küme merkezi kümedeki bir elemandır.
Artıları:
Küme sayısı bilindiği zaman iyi çalışır.
Kategorik veri setlerini hızlı kümeler.
Büyük veri setlerini ölçekler.
Hiyerarşik Kümeleme
Verileri ikili hiyerarşik bir ağaca yerleştirir. Sonuç dendogram üzerinde görülür.
Artıları:
Kaç küme olduğu bilinmediği durumlarda işe yarar.
Seçimi görselleştirmek için kullanılır.
Kendi Kendine Planlanan Harita
YSA benzeri bir kümeleme yaklaşımıdır.
Artıları:
Büyük boyutlu verileri 2 ve 3 boyutlu olarak gösterebilir.
Verinin şeklinden bir sonuç çıkarır.
Yaygın Bilinen Yumuşak Kümeleme Algoritmaları
Fuzzy c-Means
Verilerin birden fazla kümeye dahil olmaları durumunda kullanılır.
Artıları:
-Küme sayısı bilindiğinde iyi çalışır
-Örüntü tanımada iyi çalışır.
-Kümeler üst üste ise iyi çalışır.
Gaussian Mixture Model
Veri noktalarının belirli olasılıklarla farklı çok değişkenli normal dağılımlardan geldiği bölüm bazlı kümelemedir.
Artıları:
-Bir veri noktası birden fazla kümeye ait olduğunda iyi çalışır.
-Kümeler farklı boyutlara ve korelasyon yapılarına sahip olduklarında iyi çalışır.
Yaygın Boyut Azaltma Teknikleri
Temel Bileşen Analizi(Principal component analysis (PCA)
Çok boyutlu verileri kısmi kayıplarla daha küçük boyutlarla ifade etmek için yapılan işlemlerdir. Örnek için tıklayınız
Faktör Analizi (Factor analysis)
Negatif olmayan matris çarpanı (Nonnegative matrix factorization)
Metin madenciliğinde bir anlam ifade etmeyen kelimelerin çıkarılması bu şekilde yapılabilir.
4-Gözetimli Öğrenmeyi Uygulama(Applying Supervised Learning)
Veri setindeki bir kısım eleman ile eğitilen ve yeni girdileri bu eğitim sonucuna göre sınıflandıran modellere gözetimli öğrenme modelleri denir.
Etiketlenebilen veya kategorilenebilen verilerde sınıflandırma, sürekli değerlerde regresyon kullanılır.
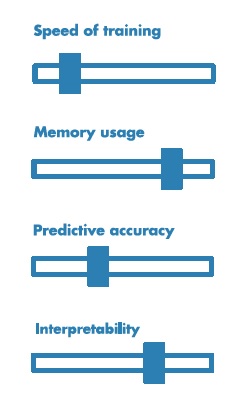
Hangi algoritmayı seçmeliyim?
Bu sorunun cevabını vermek için aşağıdaki 4 parametrenin hangilerinin öncelikli olduğunu belirlemeniz gerekmektedir.
-Eğitim hızı
-Bellek kullanımı
-Yeni bilgiyi doğru sınıflandırma
-Şeffaflık veya yorumlanabilirlik
İkili mi Çoklu mu?
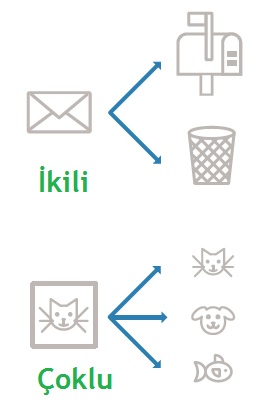
E-Postaların spam mı normal mi olduğunu belirlemek ikili, bir resimden hangi hayvan olduğunu belirlemek çoklu sınıflandırmadır.
Logistic regression gibi ikili sınıflandırmaya daha yatkın algoritmalar ikili sınıflandırmada daha başarılıdır.
Yaygın Sınıflandırma Algoritmaları
Logistic Regression
İkili sınıflandırmada kullanılır, veriyi iki sınıf arasında paylaştırır.
İyi Olduğu Durumlar:
-Veri tek düzgün bir doğru ile ayrılıyorsa
-Kompleks sınıflandırma işlemlerine giriş adımı olarak
k Nearest Neighbor (kNN)
Euclidean, city block, cosine, Chebychev gibi uzaklık ölçüm birimleri kullanarak birbirine yakın olan verileri bir sınıfa dahil eder.
İyi Olduğu Durumlar:
-Basit bir algoritma lazım olduğunda
-Eğitimli modelin bellek kullanımı önemsiz olduğunda
-Eğitimli modelin tahmin hızı önemsiz olduğunda
Support Vector Machine (SVM)
Veri setini doğrusal hiperdüzlemlerle böler.
İyi Olduğu Durumlar:
-2 sınıf var ise(daha fazla olan durumlarda da kullanılabilir)
-Yüksek boyutlu, doğrusal ayrılamayan verilerde
-Basit, doğru ve yorumlanabilir bir algoritmadır.
Neural Network
Yapay Sinir Ağları.
İyi Olduğu Durumlar:
-Doğrusal olmayan veriler içeren problemlerde
-Verinin sürekli arttığı durumlarda
-Veride beklenmeyen değişimler olduğunda
-Yorumlanabilirlik önemli olmadığı durumlarda
Naïve Bayes
Bütün verileri birbirleriyle alakasız sayarak aralarındaki olasılık oranlarına göre sınıflandırma yapar.
İyi Olduğu Durumlar:
-Çok sayıda parametresi olan küçük veri setlerinde
-Kolay yorumlanabilir bir sistem lazım olduğunda
-Eğitim verilerinde olmayan durumlarda
Discriminant Analysis
Özellikler arası doğrusal kombinasyonlar bularak sınıflandırma işlemi yapar. Diskriminant analizi, farklı sınıfların Gauss dağılımlarına dayanan veri ürettiğini varsaymaktadır. Doğrusal veya ikinci dereceden sınırlar oluşturulur ve bu sınırlara göre sınıflandırma işlemi yapılır.
İyi Olduğu Durumlar:
-Kolay yorumlanabilir
-Eğitim sırasında bellek kullanımı önemliyse
-Hızlı tahmin edecek bir yöntem lazımsa
Decision Tree
Karar Ağacı
İyi Olduğu Durumlar:
-Kolay yorumlanabilir ve hızlı
-Bellek kullanımı minimumdur
-Doğruluk çok önemli değilse (:D Bu nasıl bir öne çıkan özellikse artık 😉 )
Bagged and Boosted Decision Trees
Bir çok zayıf karar ağacı bir araya getirilerek güçlü bir karar ağacı oluşturulur.
Torbalı bir karar ağacı, bağımsız olarak girdi verilerinden önyüklenmiş olan veriler üzerinde eğitilmiş ağaçlardan oluşur.
Yükseltme, “zayıf” öğrenicileri tekrar tekrar ekleyerek ve yanlış sınıflandırılmış örneklere odaklanmak için her zayıf öğrenicinin ağırlığını ayarlayarak güçlü bir öğrenici yaratmayı içerir.
İyi Olduğu Durumlar:
-Tahmin edilecek durum kategorikse ve doğrusal değilse
-Eğitim için geçen süre daha az önemliyse
Örnek Uygulama: Üretim Ekipmanları için Öngörüleyici Bakım

365 gün 24 saat 900 işçiyle çalışan yılda 18 milyon ton plastik malzeme üreten bir fabrikadaki üretim ekipmanları takip altına alınmış ve arıza vermeden uyarı vermeleri sağlanmaya çalışılmıştır.
Neural networks, k-nearest neighbors, bagged decision trees, support vector machines (SVMs) kullanılmış en başarılı sonuçları bagged decision trees vermiştir.
Yaygın Regresyon Algoritmaları
Linear Regression
İstatistiksel olarak veriler arasında bağlanımları ortaya koyar.
İyi Olduğu Durumlar:
-En temel regresyon işlemidir, diğer adımlara geçmeden uygulanır
-Kolay yorumlanabilir ve hızlı çözüm üretir.
Nonlinear Regression
Doğrusal olmayan veriler arasında bağlanımları ortaya koyan istatistiksel bir yaklaşımdır.
İyi Olduğu Durumlar:
-Veri doğrusal değilse ve doğrusal hale getirilmesi zor ise
-Özel modellerin verilere uyumu için
Gaussian Process Regression Model
Süreç tahmininde kullanılır. Kriging olarak ta bilinir.
İyi Olduğu Durumlar:
-Yer altı suyunun dağılımı için hidrojeolojik veriler gibi mekansal verilerin enterpolasyonu için
-Otomotiv motorları gibi karmaşık tasarımların optimizasyonunu kolaylaştırmak için vekil bir model olarak
SVM Regression
SVM gibi çalışır fakat sürekli değerleri tahmin edecek şekilde ayarlanmıştır.
İyi Olduğu Durumlar:
-Yüksek boyutlu veriler için (çok sayıda öngörme değişkeni bulunur)
Generalized Linear Model
Genelleştirilmiş bir doğrusal model doğrusal yöntemleri kullanan doğrusal olmayan modellerin özel bir durumudur. Girişlerin lineer bir kombinasyonunu, çıktıların doğrusal olmayan bir fonksiyonuna (bağlantı fonksiyonu) uydurmayı içerir.
İyi Olduğu Durumlar:
-Çıktı değişkenleri normal olmayan dağılımlara sahip olduğunda, her zaman olumlu olması beklenen bir yanıt çıktı gibi
Regression Tree
Regresyon için karar ağaçları sınıflandırma için karar ağaçlarına benzer, ancak sürekli tepkileri öngörebilecek şekilde değiştirilmiştir.
İyi Olduğu Durumlar:
-Kategorik (ayrık) veriler olduğunda veya doğrusal olmayan durumlarda
Model performansını artırmak için:
-Feature selection
-Feature transformation
-Hyperparameter tuning
yapılabilir.
ASKON Konya’da MEVKA TeknoGirişim Girişimci-Yatırımcı Buluşmaları’na katıldım
ASKON Konya’nın MEVKA TeknoGirişim Girişimci-Yatırımcı Buluşmaları kapsamında 23 Ağustos 2023 Çarşamba günü ASKON Konya şubesinde>>>
Ağu
Matlab’da matrisin tüm elemanlarını belirli bir sayıdan nasıl çıkarırız?
Elimizde doğruluk oranlarının olduğu bir k matrisi olduğu varsayalım, bu matris içerisindeki tüm değerleri 1>>>
Şub
Matlab’ta iç içe döngüyle matris gezerek istediğimiz veriyi nasıl buluruz?
Başlık tam ifade eder mi bilmiyorum ama benim ihtiyacım olan şey 10 sütun, 1593 satıra>>>
Şub
A Review on Deep Learning-Based Methods Developed for Lung Cancer Diagnosis
Yüksek Lisans öğrencilerimden Türkan Beyza KARA’nın sunmuş olduğu “A Review on Deep Learning-Based Methods Developed>>>
Oca
İlk yabancı yazarlı ortak makalem yayınlandı
Birbirimizi hiç görmeden ve sesli olarak da hiç konuşmadan e-posta üzerinden tanışıp ortak bir çalışma>>>
4 Comments
Eki
Konya’da göz lazer ameliyatı oldum
25 yıldır takmakta olduğum ve kendisinden ayrılırken 6,5 numara olan gözlüğüme Konya’da göz lazer ameliyatımı>>>
Ağu
Tek kelimeyle beni nasıl tanımladılar?
YouTube üzerinden yapmış olduğum bir yoruma gelen yanıtta “…dürüst olun…” içeriğini görünce aklıma geçtiğimiz günlerde>>>
3 Comments
Ağu
Konya Akıllı Şehir HACKATHON’unda 3.olduk
Kısaca daha önceki yazımda bahsettiğim Konya Akıllı Şehir HACKATHON’unda 3.olduk. Selçuk Üniversitesi Teknoloji Fakültesi Bilgisayar>>>
1 Comment
May
Sentius ekibi olarak, Akıllı Şehir HACKATHON’una katıldık
Konya Akıllı Şehir HACKATHON’unda 3.olduk Konya Bilim Merkezi ile GDG Konya’nın düzenlediği Akıllı Şehir HACKATHON’una>>>
1 Comment
May
BİLMÖK 2022 için yazılmış gecikmiş bir yazı :)
Türkiye’nin en büyük öğrenci kongresi BİLMÖK 21-23 Mayıs 2022 günlerinde Konya’da Konya Teknik Üniversitesi’nin organizasyonuyla>>>
May
Genç Bakış Gazetesi’nden Beyzanur Polat’ın yaptığı haber…
Genç Bakış Gazetesi’nden Beyzanur Polat’ın yaptığı haber…>>>
Kas
Binary Sooty Tern Optimization Algorithms for solving Wind Turbine Placement Problem
Binary Sooty Tern Optimization Algorithms for solving Wind Turbine Placement Problem İndirmek için tıklayınız.>>>
Eyl
Konya Model Fabrika’yı Ziyaretim ve Konya Dijital Dönüşüm
“konya dijital dönüşüm” kelimesini Google üzerinden arattığım zaman Konya Model Fabrika‘yı keşfettim. 5 Ağustos 2021>>>
Ağu
Otomatlar, Biçimsel Diller ve Turing Makineleri – Dr. Emre Sermutlu – Cinius Yayınları
2020-2021 bahar yarıyılında Otomata Teorisi ve Biçimsel Diller dersini verirken kullanmam için Selçuk Üniversitesi Teknoloji>>>
Mar
4-6 MART 2021 ÇEVRİMİÇİ TÜBİTAK-2237-B PROJE EĞİTİMİ ETKİNLİĞİ KTÜ – TRABZON
Alanında dünyada öncü Prof. Dr. Yener EYÜBOĞLU, Prof. Dr. Asım KADIOĞLU, Prof. Dr. Nurettin YAYLI,>>>
Mar
ARDEB 1001 – 2020 Sonuçlarını Değerlendirme ve Yenilikler Toplantısı
>>>
Şub
2021 yılı içerisinde değerlendirilebilecek konferanslar
GLOBAL CONFERENCE on ENGINEERING RESEARCH online 2-5 June 2021 Abstract or Full Paper Submission: 2>>>
Şub
Sayfamda paylaştığım bütün Karikatürler silinmiştir
İsimsiz bir uyarı yorumuyla araştırdığım vakit gördüm ki bazı karikatüristler blog sayfalarında karikatür paylaşanlara dava>>>
Oca
MATLAB – Error: Functions cannot be indexed using {} or . indexing.
data = get(z9).OutputData{1}; satırında aşağıdaki şekilde hata vermekteydi. Error: Functions cannot be indexed using {}>>>
Oca
“ERASMUS+ Yüksek Öğretim” konulu seminer notları
“ERASMUS + Yüksek Öğretim” konulu seminer notları Dr. Öğretim Üyesi Kemal TÜTÜNCÜ hocam tarafından sunulan>>>
Oca