
“Parallel differential evolution with self-adapting control parameters and generalized opposition-based learning for solving high-dimensional optimization problems” başlıklı çalışma Wang Hui, Shahryar Rahnamayan ve Zhijian Wu tarafından yapılmış olup Journal of Parallel and Distributed Computing dergisinin 2013 yılındaki 73.sayısının 62-73.sayfaları arasında basılmıştır.
Evrimsel algoritmaların hemen hemen hepsi boyutsallık laneti(curse of dimensionality) ile cebellleşmektedir. Arama uzayının boyutu arttıkça çözüm kalitesi düşmektedir.
Java’da oluşturulan bir kod CEC-2010 benchmark fonksiyonlarını 104 saatte çözmüştür. Bu durum problemlerin çözümüne ulaşılsa dahi efektif bir zamanda ulaşılama problemini ortaya çıkarmaktadır.
Çalışmada DE algoritması GPU üzerinden paralelleştirilmiştir ve (GOjDE) ismi önerilmiştir. Bu çalışma daha önce önerilen generalized opposition based differential evolution (GODE) çalışmasının geliştirilmesiyle ortaya çıkmıştır. [H. Wang, Z.J. Wu, S. Rahnamayan, Enhanced opposition-based differential evolution for solving high-dimensional continuous optimization problems, Soft Comput. 15 (11) (2011) 2127–2140.]
Çalışmada algoritmanın performansını en üst düzeye çıkarmak için kendi kendine uyarlanan bir parametre ayarlama stratejisi önerilmiştir. GOjDE’yi hızlandırmak için GPU üzerinde gerçeklenmiştir.
CUDA programming model
1-Host and Device
2-Kernels
3-Thread Hierarchy
4-Memory Hierarchy
Thread-Block-Grid Yapısı

Opposition-based Learning (OBL) : Karşıtlığa dayalı öğrenme stratejisinde mevcut çözümün karşısına muhalif bir aday çözüm üretilir.
DE algoritmasının önemli parametrelerinden F ve CR için kendinden adapte mekanizma(self-adapting parameter mechanism) önerilmiştir. F değeri büyük ölçekli problemlerin çözümünde hassas bir parametredir çünkü adım boyutuna etki etmektedir.
Literatürde yapılan deneysel çalışmalarda F için [0.2, 0.4] önerilmiştir, bu çalışmada F=0,2 olarak alınmıştır. CR için ise [0.8, 1.0] önerilmiştir. Çalışmada [0.8, 1.0] aralığında rastgele değer alması sağlanmıştır.
The GOjDE Algorithm (CPU Implementation)

Çalışmada popülasyon çeşitliliğini artırmak için GOBL mekanizması önerilmiştir. Belirlenen değer ile rastgele üretilen bir sayının karşılaştırılması sonucunda GOBL mekanizması çalışır ya da çalışmaz. F ve CR parametreleride her jenerasyonda kendi kendilerini ayarlamaktadır.
Çalışmanın GPU üzerinde gerçeklenmesi (Implementation of parallel GOjDE on GPU)
DE_Kernel()
-Parametrelerin güncellenmesi
-Mutasyon
-Crossover
-Fitness Evoluation
-Selection
Yukarıdaki işlemler bireyler arasında bir ilişki olmadan hesaplanabildiğinden paralel programlamaya uygundur.
Update_Boundaries_Kernel()
P ve GOP popülasyonlarındaki bireyler karşılaştırılır ve hangisi daha fit ise ilgili eleman yeni popülasyona aktarılır.
Opposition_Kernel()
Karşıt bireyler oluşturulur.
Selection_Kernel()
Seçim işlemi yapısı itibariyle bağımsız değildir. O yüzden mevcut popülasyon(P) ve karşıt popülasyon(GOP) birleştirilir ve karşılaştırma işlemi her bir birey için diğer tüm bireylerle karşılaştırılarak yapılır. Bu karşılaştırma sırasında bir derece verilir, eğer karşılaştırma bittiğinde verilen derece, popüasyon büyüklüğünden küçükse bu birey en fit bireylerden biridir denilir. Bu birey diğer jenerasyonda kullanılacak popülasyona aktarılır.
Paralel seçim işlemi:

The GOjDE Implemented on GPU (GPU_GOjDE)

Kullanılan Test Fonksiyonları:

Çalışmada ilk olarak;
GOjDE
-DE
-GODE
-CHC (Crossgenerational elitist selection, Heterogeneous recombination, and Cataclysmic mutation)
-G-CMA-ES (Restart Covariant Matrix Evolutionary Strategy)
çalışmalarıyla kıyaslanmıştır.
İkinci olarak CPU ve GPU uyarlamalarının süreleri karşılaştırılarak hızlanmaları tespit edilmiştir.
Üçüncü olarak popülasyon boyutunun GOjDE’nin performansına etkisi araştırılmıştır.
Comparison of GOjDE with DE, CHC, G-CMA-ES and GODE
Adil bir kıyas için diğer algoritmalarda eşit şartlarda yarıştırılmıştır.
D = 100, 200, 500 ve 1000 seçilmiştir.
MAX_FEs=5000 × D
1E−14 üzeri sayılar 0’a yuvarlanmıştır.
Boyut 1000 alındığında GOjDE, DE ve GODE, F7 ve F15’i çözememiştir. Bunun nedeni araştırıldığında fitness değerinin 10 üzeri 308’den büyük olması sebebiyle double precision float sayılarla işlem yapılamamaktadır. Çözüm olarak long double kullanılmış ve bu sorun çözülmüştür. Çalışmada Microsoft VS 2008 kullanıldığından ve double ve long double 8 byte olarak görüldüğünden bir değişim yapılamayacağından D=1000 için sonuçlar gösterilmemiştir.
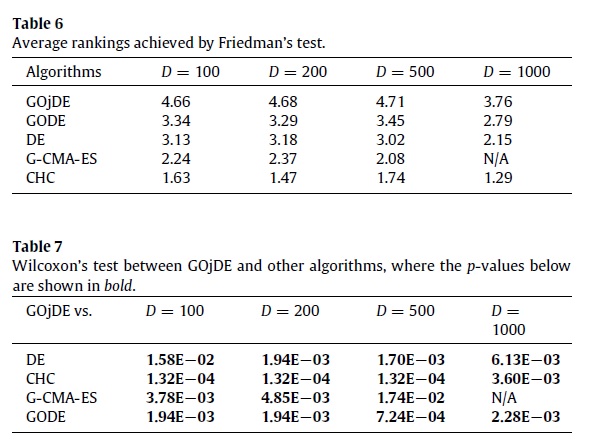
Non-parametrik testlerden Friedman ve Wilcoxon testleri algoritmaları kıyaslamak için kullanılmıştır.
GPU’da MAX_Iter = 5000×D/Np kadar çalıştırılmış. İlk çalışmada 1.15 ve 7.84 hızlanma elde edilmiş, ayrıca boyut büyüdükçe hızlanma azalmıştır. Bu beklenmeyen bir durumdur. Bunun sebebinin thread sayısının 128 ile sınırlandırılmasından dolayı olduğu anlaşılmıştır. Popülasyon sayısı=Thread sayısı alınmış ve 128 ile sınırlandırıldığından istenen performans elde edilememiştir.
256, 1024, 2048 ve 4096 şeklinde popülasyon artırılmıştır. MAX_Iter=20,000 alınmıştır. Storn ve Price popülasyon büyüklüğünü 5xD veya 10xD şeklinde önermiştir.
Çalışmayı indirmek için:
parallel_differential_evolution_with_self-adapting_control_parameters_and_generalized_opposition-based_learning_for_solving_high-dimensional_optimization_problems
ASKON Konya’da MEVKA TeknoGirişim Girişimci-Yatırımcı Buluşmaları’na katıldım
ASKON Konya’nın MEVKA TeknoGirişim Girişimci-Yatırımcı Buluşmaları kapsamında 23 Ağustos 2023 Çarşamba günü ASKON Konya şubesinde>>>
Ağu
Matlab’da matrisin tüm elemanlarını belirli bir sayıdan nasıl çıkarırız?
Elimizde doğruluk oranlarının olduğu bir k matrisi olduğu varsayalım, bu matris içerisindeki tüm değerleri 1>>>
Şub
Matlab’ta iç içe döngüyle matris gezerek istediğimiz veriyi nasıl buluruz?
Başlık tam ifade eder mi bilmiyorum ama benim ihtiyacım olan şey 10 sütun, 1593 satıra>>>
Şub
A Review on Deep Learning-Based Methods Developed for Lung Cancer Diagnosis
Yüksek Lisans öğrencilerimden Türkan Beyza KARA’nın sunmuş olduğu “A Review on Deep Learning-Based Methods Developed>>>
Oca
İlk yabancı yazarlı ortak makalem yayınlandı
Birbirimizi hiç görmeden ve sesli olarak da hiç konuşmadan e-posta üzerinden tanışıp ortak bir çalışma>>>
4 Comments
Eki
Konya’da göz lazer ameliyatı oldum
25 yıldır takmakta olduğum ve kendisinden ayrılırken 6,5 numara olan gözlüğüme Konya’da göz lazer ameliyatımı>>>
Ağu
Tek kelimeyle beni nasıl tanımladılar?
YouTube üzerinden yapmış olduğum bir yoruma gelen yanıtta “…dürüst olun…” içeriğini görünce aklıma geçtiğimiz günlerde>>>
3 Comments
Ağu
Konya Akıllı Şehir HACKATHON’unda 3.olduk
Kısaca daha önceki yazımda bahsettiğim Konya Akıllı Şehir HACKATHON’unda 3.olduk. Selçuk Üniversitesi Teknoloji Fakültesi Bilgisayar>>>
1 Comment
May
Sentius ekibi olarak, Akıllı Şehir HACKATHON’una katıldık
Konya Akıllı Şehir HACKATHON’unda 3.olduk Konya Bilim Merkezi ile GDG Konya’nın düzenlediği Akıllı Şehir HACKATHON’una>>>
1 Comment
May
BİLMÖK 2022 için yazılmış gecikmiş bir yazı :)
Türkiye’nin en büyük öğrenci kongresi BİLMÖK 21-23 Mayıs 2022 günlerinde Konya’da Konya Teknik Üniversitesi’nin organizasyonuyla>>>
May
Genç Bakış Gazetesi’nden Beyzanur Polat’ın yaptığı haber…
Genç Bakış Gazetesi’nden Beyzanur Polat’ın yaptığı haber…>>>
Kas
Binary Sooty Tern Optimization Algorithms for solving Wind Turbine Placement Problem
Binary Sooty Tern Optimization Algorithms for solving Wind Turbine Placement Problem İndirmek için tıklayınız.>>>
Eyl
Konya Model Fabrika’yı Ziyaretim ve Konya Dijital Dönüşüm
“konya dijital dönüşüm” kelimesini Google üzerinden arattığım zaman Konya Model Fabrika‘yı keşfettim. 5 Ağustos 2021>>>
Ağu
Otomatlar, Biçimsel Diller ve Turing Makineleri – Dr. Emre Sermutlu – Cinius Yayınları
2020-2021 bahar yarıyılında Otomata Teorisi ve Biçimsel Diller dersini verirken kullanmam için Selçuk Üniversitesi Teknoloji>>>
Mar
4-6 MART 2021 ÇEVRİMİÇİ TÜBİTAK-2237-B PROJE EĞİTİMİ ETKİNLİĞİ KTÜ – TRABZON
Alanında dünyada öncü Prof. Dr. Yener EYÜBOĞLU, Prof. Dr. Asım KADIOĞLU, Prof. Dr. Nurettin YAYLI,>>>
Mar
ARDEB 1001 – 2020 Sonuçlarını Değerlendirme ve Yenilikler Toplantısı
>>>
Şub
2021 yılı içerisinde değerlendirilebilecek konferanslar
GLOBAL CONFERENCE on ENGINEERING RESEARCH online 2-5 June 2021 Abstract or Full Paper Submission: 2>>>
Şub
Sayfamda paylaştığım bütün Karikatürler silinmiştir
İsimsiz bir uyarı yorumuyla araştırdığım vakit gördüm ki bazı karikatüristler blog sayfalarında karikatür paylaşanlara dava>>>
Oca
MATLAB – Error: Functions cannot be indexed using {} or . indexing.
data = get(z9).OutputData{1}; satırında aşağıdaki şekilde hata vermekteydi. Error: Functions cannot be indexed using {}>>>
Oca
“ERASMUS+ Yüksek Öğretim” konulu seminer notları
“ERASMUS + Yüksek Öğretim” konulu seminer notları Dr. Öğretim Üyesi Kemal TÜTÜNCÜ hocam tarafından sunulan>>>
Oca