
“GPU based parallel cooperative particle swarm optimization using C-CUDA: a case study.” başlıklı çalışma Kumar, Jitendra, Lotika Singh ve Sandeep Paul tarafından yapılmış olup Fuzzy Systems (FUZZ), 2013 IEEE International Conference on. IEEE konferansında 2013 yılında sunulmuştur.
Evrimsel algoritmaları CUDA üzerinde gerçeklemenin hızlanmaya katkısı olduğu gibi, yakınsama zamanında iyileşme(improvement in convergence time) yaptığı da görülmektedir.
Çalışmada CUDA üzerinde Cooperative Particle Swarm Optimization (CPSO) algoritması gerçeklenmiştir.
Çalışmada CUDA’nın randomize sınıfının popülasyon çeşitliliğini daha iyi ürettiği belirtilmiştir.
CPSO çalışması: van den Bergh, Frans, Andries P. Engelbrecht, and A. P. Engelbrecht. “Cooperative learning in neural networks using particle swarm optimizers.” South African Computer Journal. 2000. APA
CUDA(COMPUTE UNIFIED DEVICE ARCHITECTURE)
CUDA, NVIDIA tarafından geliştirilmiş bir yazılım ve donanım mimarisidir. CUDA, SIMD (Single Instruction Multiple Data) programlama modeline uygun çalışma gösterir. CPU ve GPU birlikte işleme yapar. Aynı anda çok sayıda thread çalıştığından SIMT (Single Instruction Multiple Threads) programlama modeli şeklinde isimlendirilmiştir.
GPU’da çalışan koda kernel ismi verilmektedir. Kodun bir de CPU’da çalışan kısmı mevcuttur.
CUDA grid, block ve thread yapısı
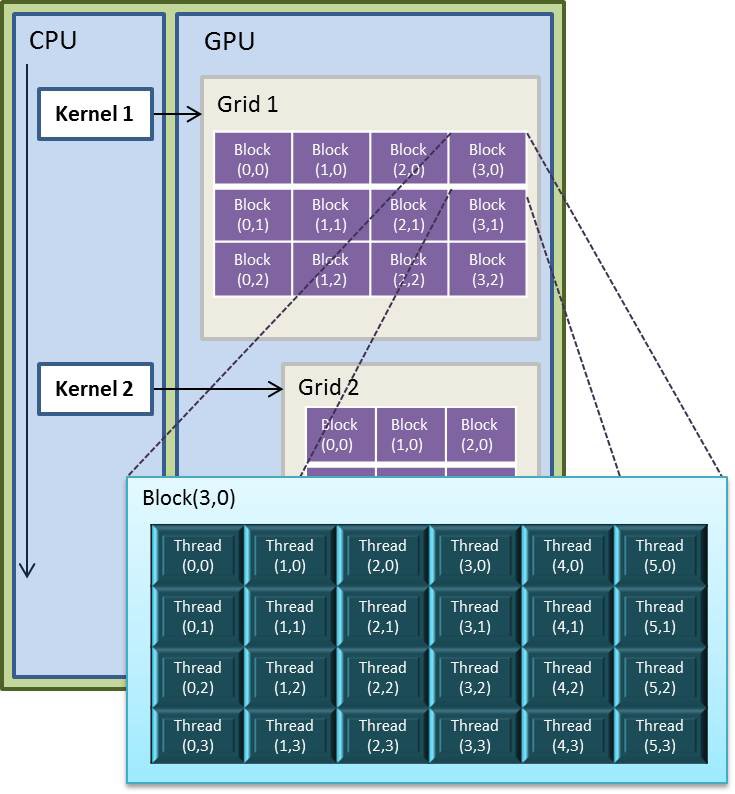
GPU bellek hiyerarşisi aşağıda görülmektedir.

Evrimsel algoritmaların fitness değerlendirme işlemi GPU’da yapılarak zaman kazanımı sağlanmaktadır.
Cooperative Particle Swarm Optimization (CPSO)
Kooperatif PSO’da parçacıklar arasında bir yarıştan ziyade yardımlaşma fikri ön plana çıkarılmıştır. Popülasyon n farklı alt popülasyona bölünür ve her bir alt bölüm ayrı ayrı çözüme ulaşmaya çalışır.
CPSO’nun bölünmüş sürü yaklaşımı:

n=5 ve D=1000 için düşünelim.
M=Parçacık Sayısı
n adet D boyutlu S1..Sn arasında sürü oluşturulur. {5 adet 1000 boyutlu sürü oluşturulur}
Durdurma kriteri sağlanıncaya kadar:
—S1–Sn sürülerinin her birinden en iyi parçacıkları seç(b1–bn)
—— For k:1-M, i:1:n
———- p=Si sürüsünün k.parçacığı
———- v =(b1;b2;:;p;:;bn) – Bir vektör oluşturulur
———- E(v)= error function at v
———- E(v)’yi kullanarak Si sürüsündeki k parçacığının fitnesini ayarla
———- b1–bn deki en iyi fitnessleri gerekliyse güncelle
—— S1–Sn sürülerinin normal PSO güncellemelerini yap
—Durdurma kriteri.
CPSO’da her bir jenerasyonda 4ns yani (2 pBest hesabı, 2 gBest hesabı)xBoyut SayısıXPopülasyon Sayısı kadar fonksiyon değerlemesi yapmaktadır. 1000 boyutlu 20 parçacıklı bir sistemde 80000 FEs yapılır. Çok fonksiyon değerlemesi yapıldığından paralel programlama çözümü uygun bir yaklaşımdır.
GPU destekli CPSO algoritmasının sözde kodu:

Paralel olarak fitness değerlemesi aşağıdaki şekilde yapılmaktadır:
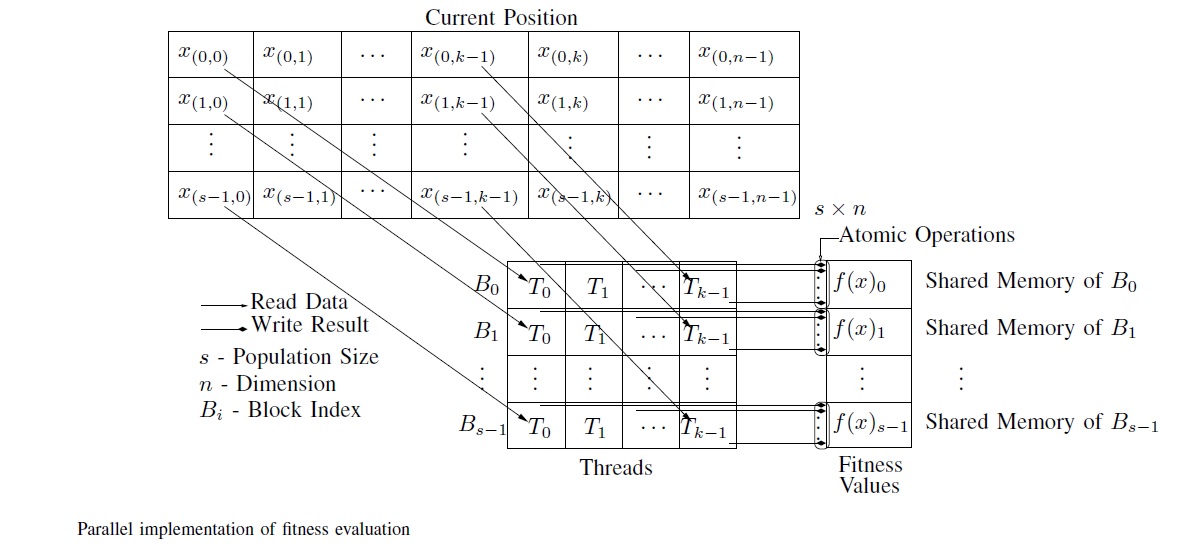
Hesaplama işlemi atomic operations ile yapılmaktadır. Böylece aynı anda aynı bölgeye tek bir yazma işlemi gerçekleştirilmektedir. Sonuçlar shared memory’ye yazılmaktadır.
context vector oluşumu aşağıdaki şekilde yapılmaktadır:

Tüm adımlar aşağıdaki şekilde görselleştirilmiştir:
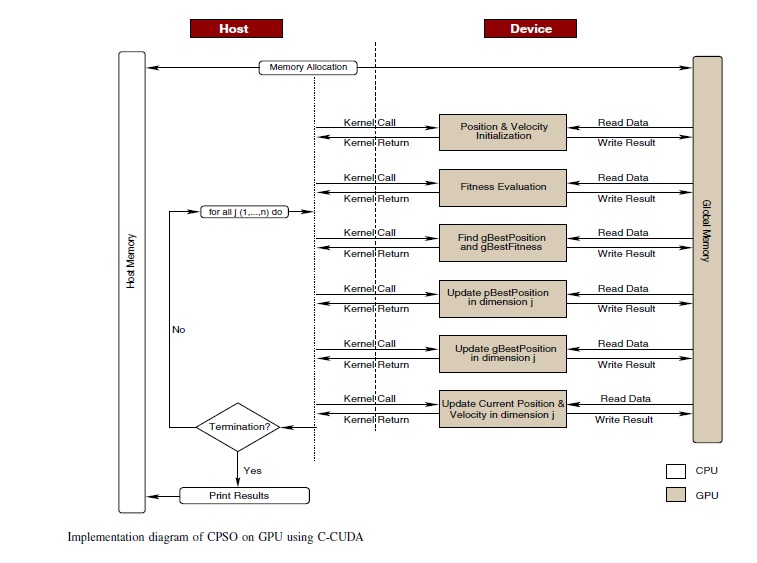
İşlemler GPU’da yapılırken organizasyon CPU tarafından yürütülmektedir.
Çalışmada ?1 = ?2 = 2.05 ve ? = 0.25 alınmıştır.
Çalışmanın yapıldığı makinanın özellikleri:

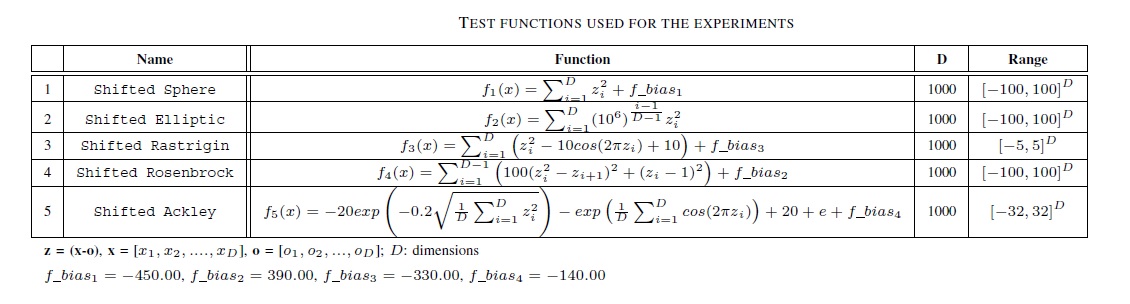
Test fonksiyonları:
CUDA’da thread/block sayısını belirlemek de önemli bir karardır. Sonuca etki etmektedir. Aşağıda farklı boyutlarda farklı thread/block sayısın etkisi görülmektedir.

100 jenerasyonda 500,1000,1500 boyutta farklı threads/block sayısına göre sonuçlar:

Her thread bir boyutta işlem yapmaktadır ve her blokta ⌈?/?⌉ Boyut/Block’taki Thread Sayısı kadar eleman işlenmektedir.
Farklı fonksiyonlarda farklı hızlanmaların elde edilmesinin nedeni fonksiyonun hesaplama karmaşıklığı ile alakalıdır.
1000 jenerasyonda ulaşılan sonuçlar:
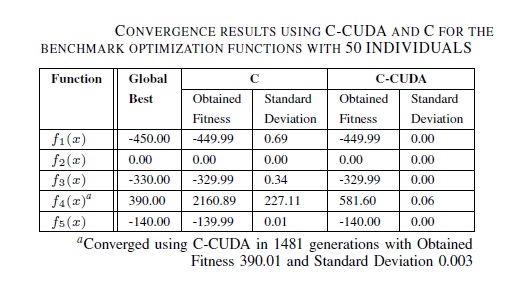
Yakınsama analizi ve popülasyon çeşitliliğini izleme adına yapılan çalışmada:

Paralel versiyonun daha iyi yakınsadığı ve daha erken istenen sonuca ulaştığı görülmektedir. Bunun nedeni olarak CUDA’nın rastgele sayı üretme tekniğinin daha iyi olduğu sonucuna varılmıştır. Ayrıca CPU’da tek noktalı bir rastgele sayı üretme durumu var iken, burada her bir GPU çekirdeği için ayrı bir rastgele sayı üretme çekirdeği vardır.
Çalışmayı indirmek için:
gpu_based_parallel_cooperative_particle_swarm_optimization_using_c_cuda_a_case_study
ASKON Konya’da MEVKA TeknoGirişim Girişimci-Yatırımcı Buluşmaları’na katıldım
ASKON Konya’nın MEVKA TeknoGirişim Girişimci-Yatırımcı Buluşmaları kapsamında 23 Ağustos 2023 Çarşamba günü ASKON Konya şubesinde>>>
Ağu
Matlab’da matrisin tüm elemanlarını belirli bir sayıdan nasıl çıkarırız?
Elimizde doğruluk oranlarının olduğu bir k matrisi olduğu varsayalım, bu matris içerisindeki tüm değerleri 1>>>
Şub
Matlab’ta iç içe döngüyle matris gezerek istediğimiz veriyi nasıl buluruz?
Başlık tam ifade eder mi bilmiyorum ama benim ihtiyacım olan şey 10 sütun, 1593 satıra>>>
Şub
A Review on Deep Learning-Based Methods Developed for Lung Cancer Diagnosis
Yüksek Lisans öğrencilerimden Türkan Beyza KARA’nın sunmuş olduğu “A Review on Deep Learning-Based Methods Developed>>>
Oca
İlk yabancı yazarlı ortak makalem yayınlandı
Birbirimizi hiç görmeden ve sesli olarak da hiç konuşmadan e-posta üzerinden tanışıp ortak bir çalışma>>>
4 Comments
Eki
Konya’da göz lazer ameliyatı oldum
25 yıldır takmakta olduğum ve kendisinden ayrılırken 6,5 numara olan gözlüğüme Konya’da göz lazer ameliyatımı>>>
Ağu
Tek kelimeyle beni nasıl tanımladılar?
YouTube üzerinden yapmış olduğum bir yoruma gelen yanıtta “…dürüst olun…” içeriğini görünce aklıma geçtiğimiz günlerde>>>
3 Comments
Ağu
Konya Akıllı Şehir HACKATHON’unda 3.olduk
Kısaca daha önceki yazımda bahsettiğim Konya Akıllı Şehir HACKATHON’unda 3.olduk. Selçuk Üniversitesi Teknoloji Fakültesi Bilgisayar>>>
1 Comment
May
Sentius ekibi olarak, Akıllı Şehir HACKATHON’una katıldık
Konya Akıllı Şehir HACKATHON’unda 3.olduk Konya Bilim Merkezi ile GDG Konya’nın düzenlediği Akıllı Şehir HACKATHON’una>>>
1 Comment
May
BİLMÖK 2022 için yazılmış gecikmiş bir yazı :)
Türkiye’nin en büyük öğrenci kongresi BİLMÖK 21-23 Mayıs 2022 günlerinde Konya’da Konya Teknik Üniversitesi’nin organizasyonuyla>>>
May
Genç Bakış Gazetesi’nden Beyzanur Polat’ın yaptığı haber…
Genç Bakış Gazetesi’nden Beyzanur Polat’ın yaptığı haber…>>>
Kas
Binary Sooty Tern Optimization Algorithms for solving Wind Turbine Placement Problem
Binary Sooty Tern Optimization Algorithms for solving Wind Turbine Placement Problem İndirmek için tıklayınız.>>>
Eyl
Konya Model Fabrika’yı Ziyaretim ve Konya Dijital Dönüşüm
“konya dijital dönüşüm” kelimesini Google üzerinden arattığım zaman Konya Model Fabrika‘yı keşfettim. 5 Ağustos 2021>>>
Ağu
Otomatlar, Biçimsel Diller ve Turing Makineleri – Dr. Emre Sermutlu – Cinius Yayınları
2020-2021 bahar yarıyılında Otomata Teorisi ve Biçimsel Diller dersini verirken kullanmam için Selçuk Üniversitesi Teknoloji>>>
Mar
4-6 MART 2021 ÇEVRİMİÇİ TÜBİTAK-2237-B PROJE EĞİTİMİ ETKİNLİĞİ KTÜ – TRABZON
Alanında dünyada öncü Prof. Dr. Yener EYÜBOĞLU, Prof. Dr. Asım KADIOĞLU, Prof. Dr. Nurettin YAYLI,>>>
Mar
ARDEB 1001 – 2020 Sonuçlarını Değerlendirme ve Yenilikler Toplantısı
>>>
Şub
2021 yılı içerisinde değerlendirilebilecek konferanslar
GLOBAL CONFERENCE on ENGINEERING RESEARCH online 2-5 June 2021 Abstract or Full Paper Submission: 2>>>
Şub
Sayfamda paylaştığım bütün Karikatürler silinmiştir
İsimsiz bir uyarı yorumuyla araştırdığım vakit gördüm ki bazı karikatüristler blog sayfalarında karikatür paylaşanlara dava>>>
Oca
MATLAB – Error: Functions cannot be indexed using {} or . indexing.
data = get(z9).OutputData{1}; satırında aşağıdaki şekilde hata vermekteydi. Error: Functions cannot be indexed using {}>>>
Oca
“ERASMUS+ Yüksek Öğretim” konulu seminer notları
“ERASMUS + Yüksek Öğretim” konulu seminer notları Dr. Öğretim Üyesi Kemal TÜTÜNCÜ hocam tarafından sunulan>>>
Oca