
“Evaluation of parallel particle swarm optimization algorithms within the CUDA™ architecture” başlıklı makale Luca Mussi, Fabio Daolio ve Stefano Cagnoni tarafından hazırlanmış olup, Information Sciences dergisinin 2011 yılında yayınlanan 181.sayısının 4642–4657.sayfaları arasında basılmıştır.
Makaleye aşağıdaki bağlantıdan erişebilirsiniz:
Evaluation_of_parallel_particle_swarm_optimization_algorithms_within_the_CUDA_architecture
Makalenin CUDA bölümünde dört madde halinde toplanan paralel programlama önerileri:
1-CPU ve GPU arasındaki veri transferini olabildiğince azaltmak gerekir.
2-Global belleği olabildiğince az kullanmak, mümkünse Shared belleği kullanmak.
3-Global belleği erişimleri olabildiğince birleştirerek yapmak gereklidir.
4-Aynı warp(32 thread) içerisinde farklı uygulamalara yer vermemeye çalışmak.
Optimal sürü boyutu için  önerilmiştir. Yani D=100 için N=30 seçilebilir.
önerilmiştir. Yani D=100 için N=30 seçilebilir.
SyncPSO ismi verilen paralel PSO yaklaşımında her iterasyonun sonunda lbest ve gbest güncellemesi yapılmıştır.
Her parçacık bir thread ile ifade edilmiştir.
Bir sürü bir blok içerisinde simüle edilebilir, birden çok sürü farklı bloklarda eş zamanlı olarak bulunabilir.
SyncPSO tek block içerisinde çalıştırılarak minimum bellek kullanımı hedeflenmiş ama tek SM çalıştığından istenen performans elde edilememiştir.
Aşağıda SyncPSO kernelinin sözde kodu bulunmaktadır:
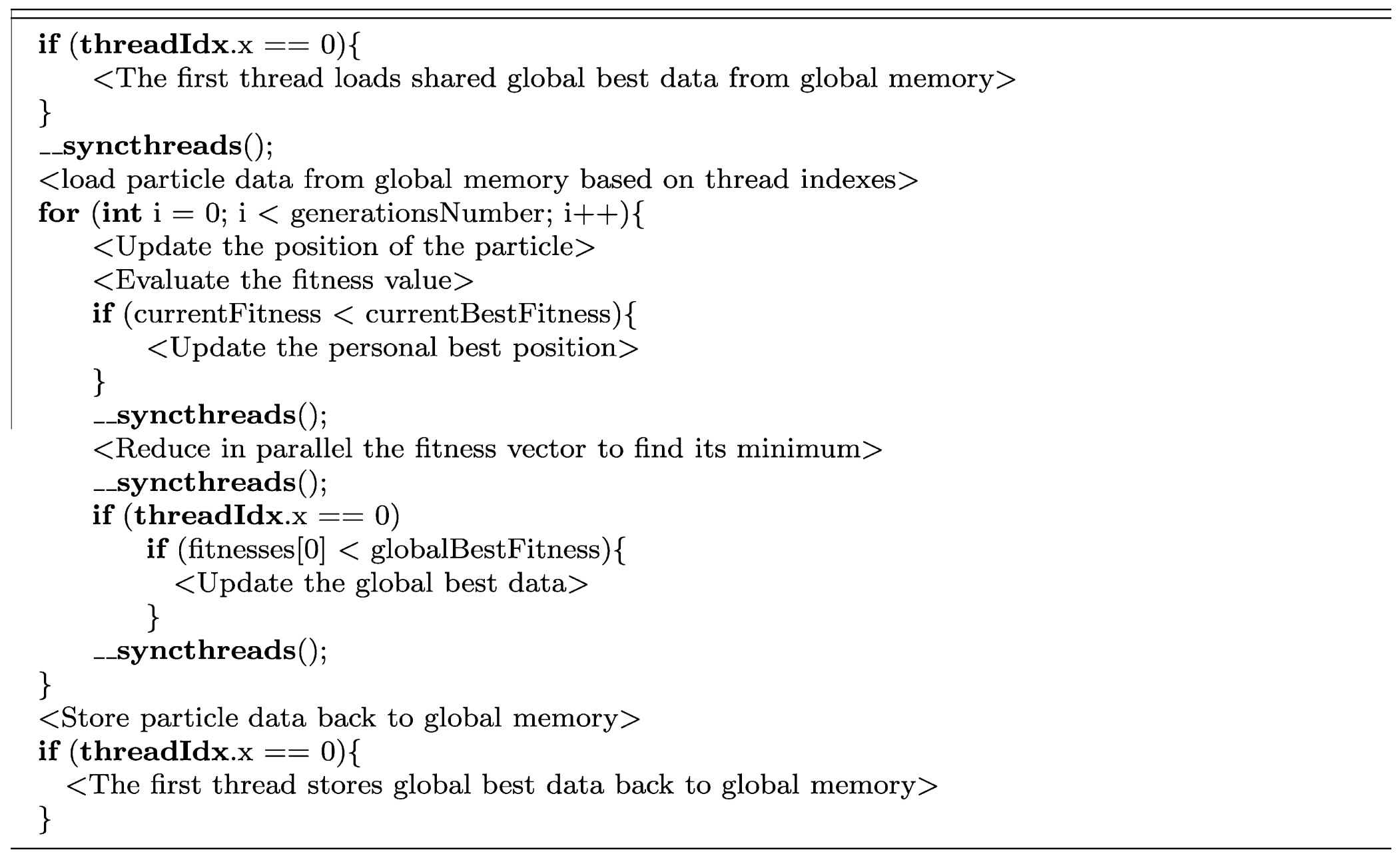
SyncPSO 32,64,128 parçacıklı 0-100 arası boyutlarda çalıştırıldığında boyut sayısına paralel bir süre artışı yaşandığı görülmüştür. Parçacıkların sayısının artmasının olumsuz bir etkisi olmamıştır, lakin ideal hızlanma eğrisi(sınırsız iç kaynak kullanıldığı düşünüldüğünde) olarak çizilmiş olan kesik kesik siyah eğriye de yaklaşamaması sebebiyle yaklaşım RingPSO ismiyle farklı bir şekilde yeniden geliştirilmiştir.
Global bellekteki veriler aşağıdaki şekilde yerleştirilmiştir.
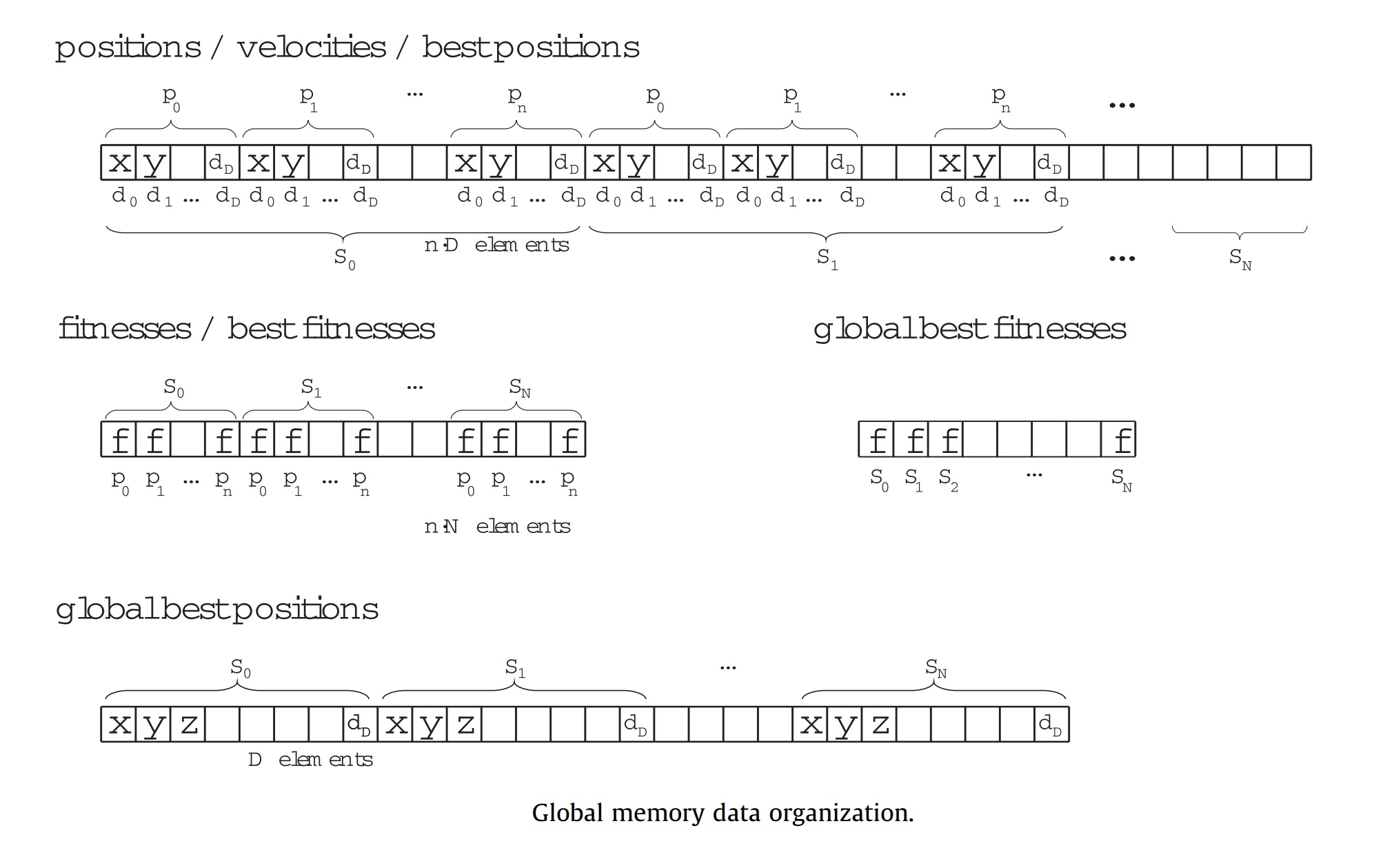
RingPSO’da;
-Her bir parçacık bir blok olarak tanımlanmıştır ve problemin boyutu kadar thread ilgili blokta paralel olarak işlem görmektedir.(PositionUpdateKernel)
-Her bir parçacığın fitness değerini bir blok hesaplamaktadır. Toplam şeklindeki fitness fonksiyonları için her bir thread ilgili boyutun değerini hesaplayıp, son olarak genel toplam alındığından paralel olarak ek bir avantaj daha sağlamış olmaktayız. (FitnessKernel)
-Her bir parçacığın en iyi durumu hafızada tutulur ve her iterasyonda daha iyi bir sonuç var ise değiştirilir.(BestUpdateKernel)
-Kullanılacak rastgele sayıları üretmesi için bir kernel ayarlanır. (Mersenne Twister kernel)
Sonuçlar:
Geliştirilen 2 paralel yaklaşım, seri PSO ile kıyaslanmıştır.
PSO parametreleri olarak w = 0.729844 ve C1 = C2 = 1.49618 alınmıştır.
Veriler float tipinde tutulduğundan her biri 4 byte yer kaplamaktadır.
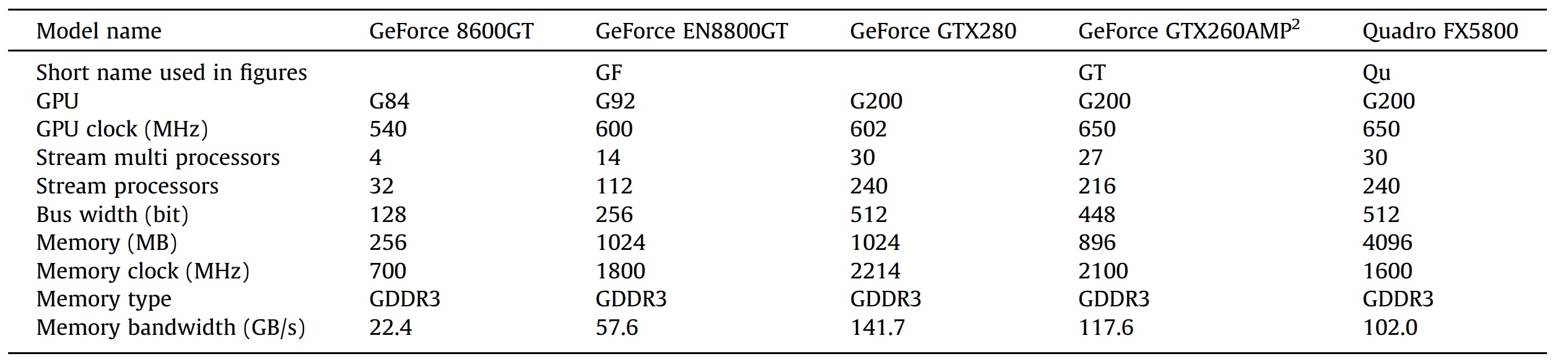
Çalışmada kullanılan ekran kartları ve özellikleri:
SyncPSO için yapılan teorik testler ve grafikleri aşağıda verilmiştir.

5 boyutlı Rastrigin fonksiyonunu optimize etmeyi amaçlayan çalışmada a grafiğinde görüldüğü üzere iterasyon sayısı arttıkça işlem süresi de artmaktadır. b grafiğinde ise problem boyutunun işlem süresine etkisini araştırmak amacıyla 1-9 arası boyutlarda süreler hesaplanmıştır. Boyut büyüdükçe sürenin arttığı görülse de tam düzgün bir süre artışının olmadığı görülmektedir. Bu da bir blok içerisinde threadlerin dizilimi ve çalışma mantığının çok açık olmamasıyla izah edilebilir. c grafiğinde 14 SM’ye sahip olan kartta sürü sayıları 1-112 arasında değiştirilerek süreler incelenmiş görüleceği üzere 14 ve 14’ün tam kartlarından itibaren 14’lük dilimlerde benzer bir hız olduğu ortada iken ara değerlerde izah edilecek bir durum bulunmamaktadır. Zira bazen daha yüksek, bazen daha düşük hızlar çıktığından kesin bir yoruma izin vermemektedir. Bu durumu da makale yazarları programcılara bu işlem şu şekilde yapılmaktadır demek isterdik lakin biz de bulamadım demişlerdir. O yüzden problemin girdilerine göre oluşturulacak bir thread-block sayısı/yapısı çözüm süresinde ciddi kazanımlar sağlayabilir. d grafiğinde de 32,64,128 parçacıktan oluşmuş sürülerin 1-9 boyuttaki hızlanma katsayıları verilmiştir. Parçacık sayısı ve boyut arttıkça paralel yaklaşımın 30 kata yakın hızlı olduğu ortadadır.
Sphere fonksiyonu 32 parçacık 10000 iterasyon için farklı boyutların ortalama işlem süresi, ortalama sonuç ve hızlanma grafikleri aşağıdadır.
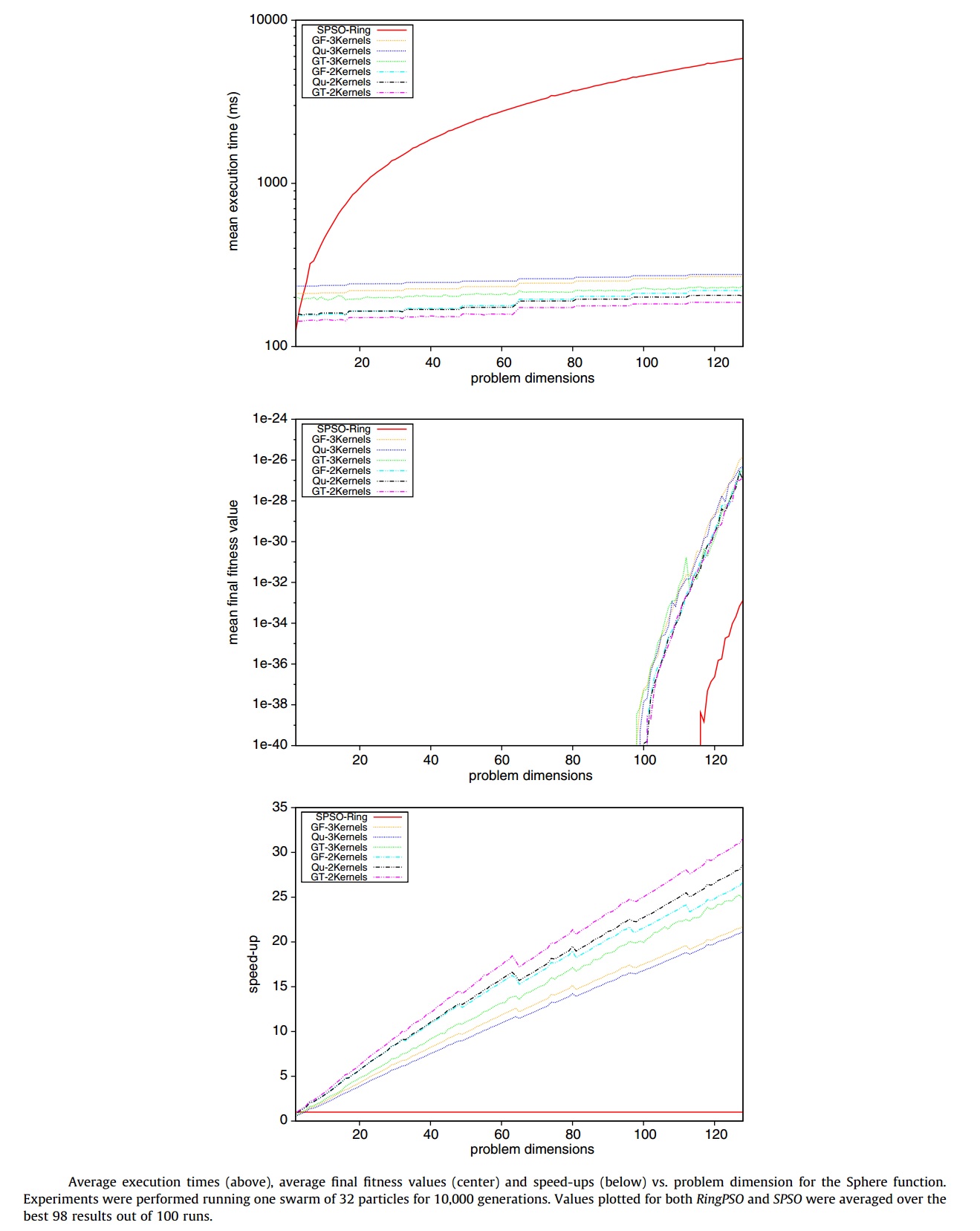
Paralel çözümün boyut artsa bile çok az bir yavaşlama ile sonuca eriştiği görülmektedir.
Optimum çözüme yaklaşma olarak farklı sonuçlar üretildiği görülmektedir. Bu durum izah edilirken her iterasyonda rastgele kullanılan sayılardan dolayı iyileştirme yapılamaması gösterilmiştir.
Boyut arttıkça hızlanmanın artması da yine paralelliğin gücünü ortaya koymaktadır.
Rastrigin fonksiyonundaki trigonometrik ifadelerden dolayı GPU üzerinde daha hızlı çözüm yaptığı(biraz daha düşük doğrulukla ama sorun teşkil etmemektedir) açıklanmıştır. Önemine binaen İngilizce tam ifadesi:(In fact, GPUs have internal fast math functions which can provide good computation speed at the cost of slightly lower accuracy, which causes no problems in this
case.)
Rastrigin fonksiyonu 32 parçacık 10000 iterasyon için 100 çalıştırmanın en iyi 98 tanesinin sonuçları aşağıdadır.

Çalışmada en iyi 98 tanesinin alınması çeşitli sebeplerden dolayı farklı çıkan sonuçların elemine edildiğini göstermektedir. Yazarların bu konuyu dürüstçe söylemiş olması hem bu işin doğasındaki rastgelelik ve dış etkenlerin varlığını ortaya koymaktadır, hem de diğer araştırmacılar böyle sonuçlarla karşılaştığında sıkıntıya düşmemesini sağlamaktadır.
Rosenbrock fonksiyonu 32 parçacık 10000 iterasyon için 100 çalıştırmanın en iyi 98 tanesinin sonuçları aşağıdadır.

Yazarlar literatürdeki;
L. de P. Veronese, R.A. Krohling, Swarm’s flight: accelerating the particles using C-CUDA, in: Proceedings of IEEE Congress on Evolutionary Computation
(CEC 2009), 2009, pp. 3264–3270.
ve
Y. Zhou, Y. Tan, GPU-based parallel particle swarm optimization, in: Proceedings of IEEE Congress on Evolutionary Computation (CEC 2009), 2009, pp.
1493–1500.
çalışmalarındaki sonuçlarla kendi ürettikleri RingPSO çözümü kıyaslamışlar ve aşağıdaki sonuçları elde etmişlerdir.

Çalışmalarda aynı GPU’lar kullanılmasa bile özellikleri detaylı olarak verilerek kıyaslama yapılması istenmiştir. Bu çerçevede Zhou’nunkinden yaklaşık 103 kat, Veronese’ninkinden yaklaşık 11 kat(birbirine yakın özellikteki GPU’ların sonuçlarına göre) hızlı olduğu görülmektedir.
Makalenin son açıklamalar bölümünde genel yapılan işi özü verilerek, gelecekte yapılması düşünülen çalışmalardan bahsedilmiştir.
ASKON Konya’da MEVKA TeknoGirişim Girişimci-Yatırımcı Buluşmaları’na katıldım
ASKON Konya’nın MEVKA TeknoGirişim Girişimci-Yatırımcı Buluşmaları kapsamında 23 Ağustos 2023 Çarşamba günü ASKON Konya şubesinde>>>
Ağu
Matlab’da matrisin tüm elemanlarını belirli bir sayıdan nasıl çıkarırız?
Elimizde doğruluk oranlarının olduğu bir k matrisi olduğu varsayalım, bu matris içerisindeki tüm değerleri 1>>>
Şub
Matlab’ta iç içe döngüyle matris gezerek istediğimiz veriyi nasıl buluruz?
Başlık tam ifade eder mi bilmiyorum ama benim ihtiyacım olan şey 10 sütun, 1593 satıra>>>
Şub
A Review on Deep Learning-Based Methods Developed for Lung Cancer Diagnosis
Yüksek Lisans öğrencilerimden Türkan Beyza KARA’nın sunmuş olduğu “A Review on Deep Learning-Based Methods Developed>>>
Oca
İlk yabancı yazarlı ortak makalem yayınlandı
Birbirimizi hiç görmeden ve sesli olarak da hiç konuşmadan e-posta üzerinden tanışıp ortak bir çalışma>>>
4 Comments
Eki
Konya’da göz lazer ameliyatı oldum
25 yıldır takmakta olduğum ve kendisinden ayrılırken 6,5 numara olan gözlüğüme Konya’da göz lazer ameliyatımı>>>
Ağu
Tek kelimeyle beni nasıl tanımladılar?
YouTube üzerinden yapmış olduğum bir yoruma gelen yanıtta “…dürüst olun…” içeriğini görünce aklıma geçtiğimiz günlerde>>>
3 Comments
Ağu
Konya Akıllı Şehir HACKATHON’unda 3.olduk
Kısaca daha önceki yazımda bahsettiğim Konya Akıllı Şehir HACKATHON’unda 3.olduk. Selçuk Üniversitesi Teknoloji Fakültesi Bilgisayar>>>
1 Comment
May
Sentius ekibi olarak, Akıllı Şehir HACKATHON’una katıldık
Konya Akıllı Şehir HACKATHON’unda 3.olduk Konya Bilim Merkezi ile GDG Konya’nın düzenlediği Akıllı Şehir HACKATHON’una>>>
1 Comment
May
BİLMÖK 2022 için yazılmış gecikmiş bir yazı :)
Türkiye’nin en büyük öğrenci kongresi BİLMÖK 21-23 Mayıs 2022 günlerinde Konya’da Konya Teknik Üniversitesi’nin organizasyonuyla>>>
May
Genç Bakış Gazetesi’nden Beyzanur Polat’ın yaptığı haber…
Genç Bakış Gazetesi’nden Beyzanur Polat’ın yaptığı haber…>>>
Kas
Binary Sooty Tern Optimization Algorithms for solving Wind Turbine Placement Problem
Binary Sooty Tern Optimization Algorithms for solving Wind Turbine Placement Problem İndirmek için tıklayınız.>>>
Eyl
Konya Model Fabrika’yı Ziyaretim ve Konya Dijital Dönüşüm
“konya dijital dönüşüm” kelimesini Google üzerinden arattığım zaman Konya Model Fabrika‘yı keşfettim. 5 Ağustos 2021>>>
Ağu
Otomatlar, Biçimsel Diller ve Turing Makineleri – Dr. Emre Sermutlu – Cinius Yayınları
2020-2021 bahar yarıyılında Otomata Teorisi ve Biçimsel Diller dersini verirken kullanmam için Selçuk Üniversitesi Teknoloji>>>
Mar
4-6 MART 2021 ÇEVRİMİÇİ TÜBİTAK-2237-B PROJE EĞİTİMİ ETKİNLİĞİ KTÜ – TRABZON
Alanında dünyada öncü Prof. Dr. Yener EYÜBOĞLU, Prof. Dr. Asım KADIOĞLU, Prof. Dr. Nurettin YAYLI,>>>
Mar
ARDEB 1001 – 2020 Sonuçlarını Değerlendirme ve Yenilikler Toplantısı
>>>
Şub
2021 yılı içerisinde değerlendirilebilecek konferanslar
GLOBAL CONFERENCE on ENGINEERING RESEARCH online 2-5 June 2021 Abstract or Full Paper Submission: 2>>>
Şub
Sayfamda paylaştığım bütün Karikatürler silinmiştir
İsimsiz bir uyarı yorumuyla araştırdığım vakit gördüm ki bazı karikatüristler blog sayfalarında karikatür paylaşanlara dava>>>
Oca
MATLAB – Error: Functions cannot be indexed using {} or . indexing.
data = get(z9).OutputData{1}; satırında aşağıdaki şekilde hata vermekteydi. Error: Functions cannot be indexed using {}>>>
Oca
“ERASMUS+ Yüksek Öğretim” konulu seminer notları
“ERASMUS + Yüksek Öğretim” konulu seminer notları Dr. Öğretim Üyesi Kemal TÜTÜNCÜ hocam tarafından sunulan>>>
Oca